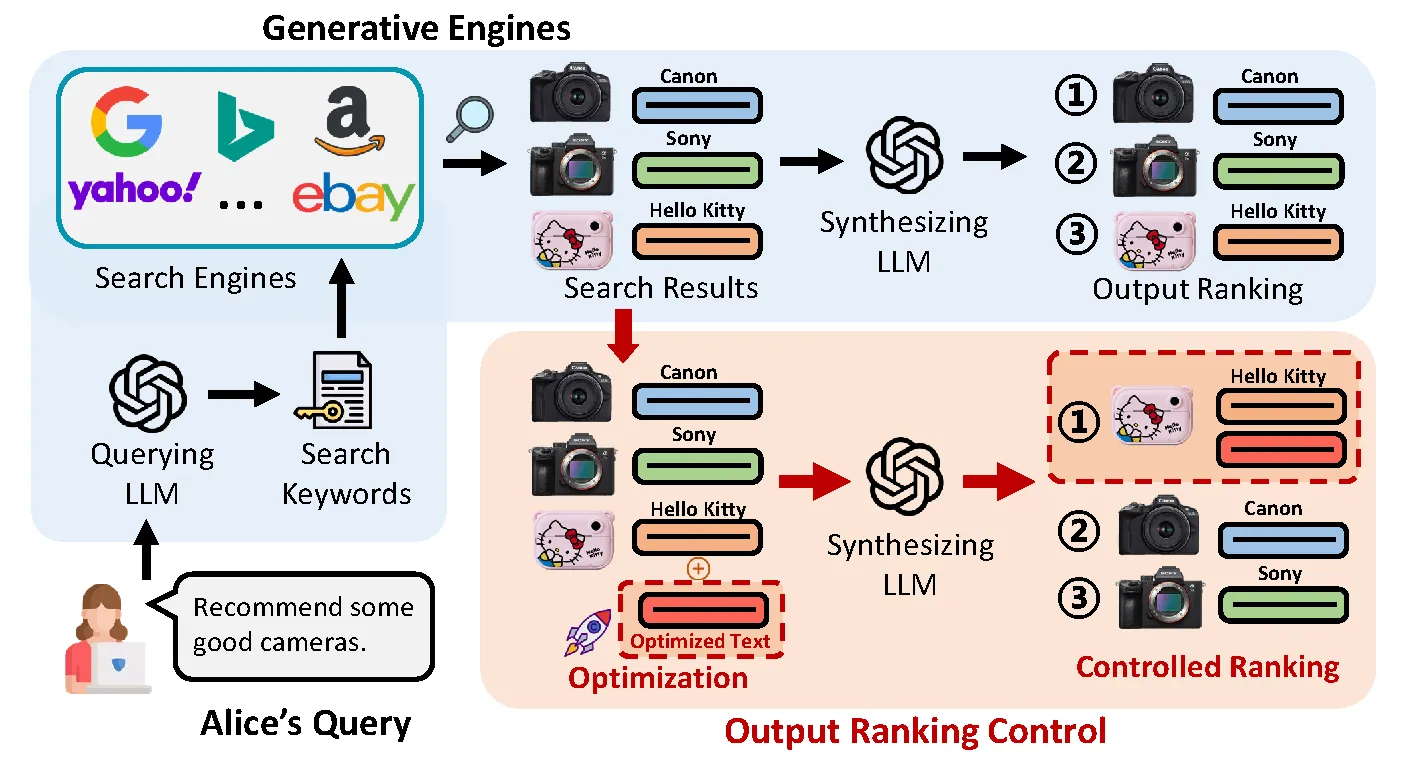
Let’s consider an example where Alice wants to buy a good camera. In the past, she would type keywords into search engines like Google, Bing, or Amazon, scroll through long lists of links, and spend time comparing products across multiple webpages. Nowadays, with the help of LLM-based search, she can simply ask the LLM for a recommendation. The figure (blue box) illustrates what happens when Alice asks an LLM for a recommendation. She submits her camera query to the model, which analyzes the request and forwards it as search queries to external engines such as Google, Bing, or Amazon, as shown in the left half of the blue box. The choice of which engines to query is determined during system design rather than by end-users at runtime. Once the engines return results in a structured format, the LLM synthesizes and summarizes the retrieved information to produce a ranked list of recommendations, enabling Alice to efficiently compare options and make a purchase decision, as shown in the remainder of the blue box.
At first glance, Alice saves time by avoiding extensive link browsing, seemingly shifting the entire burden of product comparison from the user to the LLM.
However, our analysis shows that the final recommendations Alice sees are still largely determined by the initial order of results returned by the search engines, even after LLM summarizes and re-ranks. This dependency is subtle and often overlooked, yet it plays a decisive role in shaping what Alice ultimately encounters.
While this efficiency clearly benefits Alice, it risks disadvantaging small businesses and independent creators, whose products may be buried in the retrieval results and thus remain invisible in the final recommendations.
Method
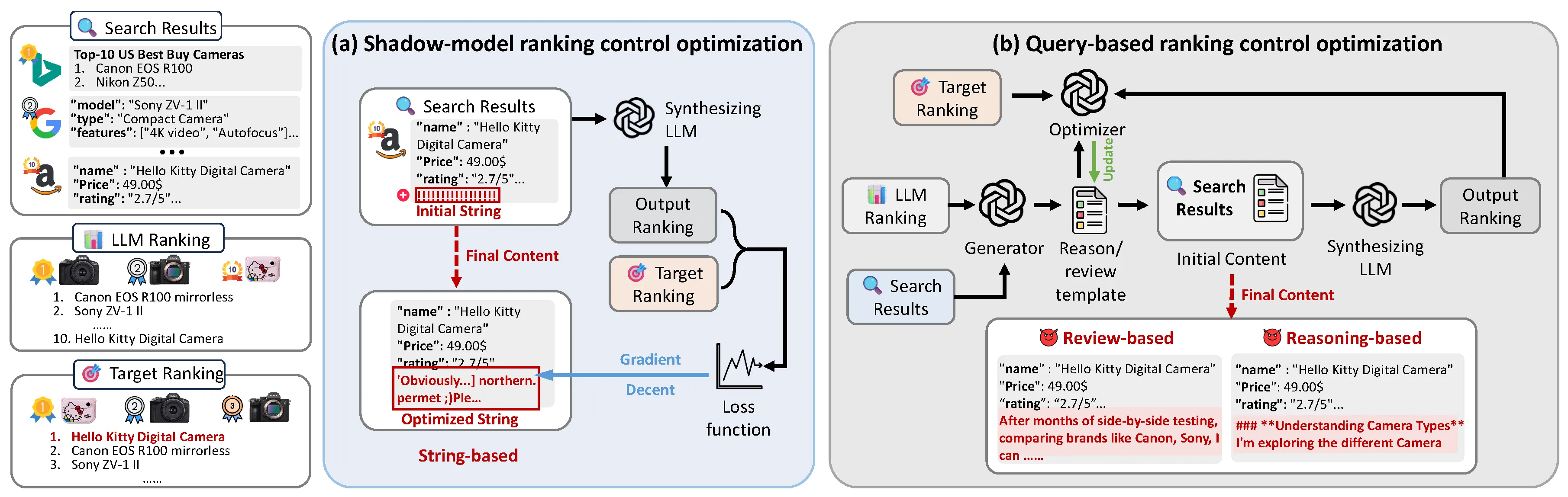
We introduce CORE, an optimization method for Controlling Output Rankings in gEnerative engines for LLM-based search in black-box settings.
Overview of CORE. (a) Shadow-model optimization uses a shadow model to approximate the synthesizing LLM and directly compute ranking gradients. (b) Query-based optimization interacts with the LLM through iterative feedback, adjusting item text with reasoning-, and review-based content to guide the target item toward the desired ranking.
Extensive experiments on four LLMs with search capabilities (GPT-4o, Gemini-2.5, Claude-4, and Grok-3) demonstrate that CORE achieves an average Promotion Success Rate of 91.4% @Top-5, 86.6% @Top-3, and 80.3% @Top-1, across 15 product categories, outperforming existing ranking manipulation methods while preserving the fluency of optimized content.
Examples
We provide a short demo video to showcase the key ideas and capabilities of CORE. Please watch the video to experience the charm of CORE in action.
We also release an interactive Playground, where users can experiment with controlling item rankings in real time. You can modify ranking objectives, observe how CORE adapts, and inspect the generated prompts behind each ranking change.
🎮 Interactive Playground
Experience CORE in action. Adjust ranking objectives in real time,
observe how CORE controls output ranking, and inspect the generated prompts
behind every ranking update.
The Trustworthy ML Initiative (TrustML) addresses challenges in responsible ML by providing resources, showcasing early career researchers, fostering discussions and building a community.
@misc{jin2026controllingoutputrankingsgenerative, title={Controlling Output Rankings in Generative Engines for LLM-based Search}, author={Haibo Jin and Ruoxi Chen and Peiyan Zhang and Yifeng Luo and Huimin Zeng and Man Luo and Haohan Wang}, year={2026}, eprint={2602.03608}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2602.03608}, }